初学者向け マルチモーダル埋め込み② ― 桜餅で「さわって体感する」ハンズオン資料をSlideShareに公開しました


2026年5月に作成したハンズオン資料「マルチモーダル埋め込みをさわってみよう ― テキスト・画像・音声を、ひとつの空間で検索する」を、SlideShare に公開しました。
https://www.slideshare.net/slideshow/gemini-embedding-2/287778884
前回は和菓子ECサイトを題材に「商品名だけ → 商品説明を追記 → 画像も投入」という3段階で検索精度がどう変わるかを検証しました。今回はもう一歩手前に戻り、「そもそも埋め込みとは何をしているのか」を、約20分で手を動かしながら体感することをねらいにしています。題材はおなじみの桜餅。それに加えて、犬の鳴き声やバナナをかじる音といった音声ファイルまで同じ土俵に乗せたのが今回の見どころです。
以下、スライドの内容をダイジェストでお届けします。
コンピューターは桜餅の「もちもち感」を理解できるか?

文字も、写真も、音も――まったく形のちがうデータを、コンピューターはどうやって「意味」で結びつけるのか。この素朴な問いが、今回のハンズオンの出発点です。答えを握るのが「埋め込み(Embedding)」という考え方です。
概念①:埋め込み(Embedding)とは
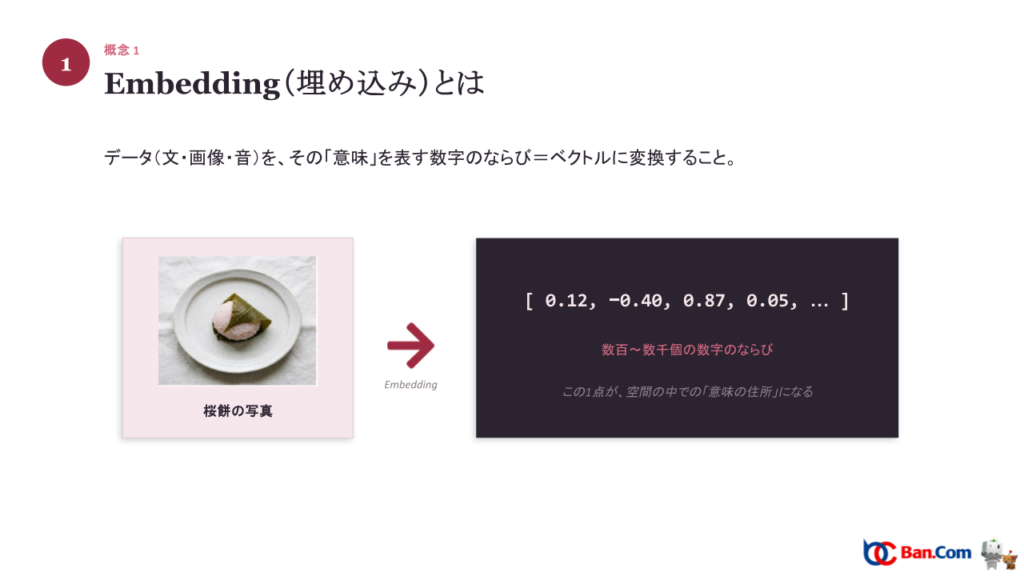
埋め込みとは、データ(文・画像・音)を、その「意味」を表す数字のならび=ベクトルに変換することです。たとえば桜餅の写真を埋め込むと [ 0.12, −0.40, 0.87, 0.05, … ] のような数百〜数千個の数字のならびになります。この1点が、空間の中での「意味の住所」になる、とイメージするとわかりやすいです。
概念②:ぜんぶ、ひとつの空間に並ぶ
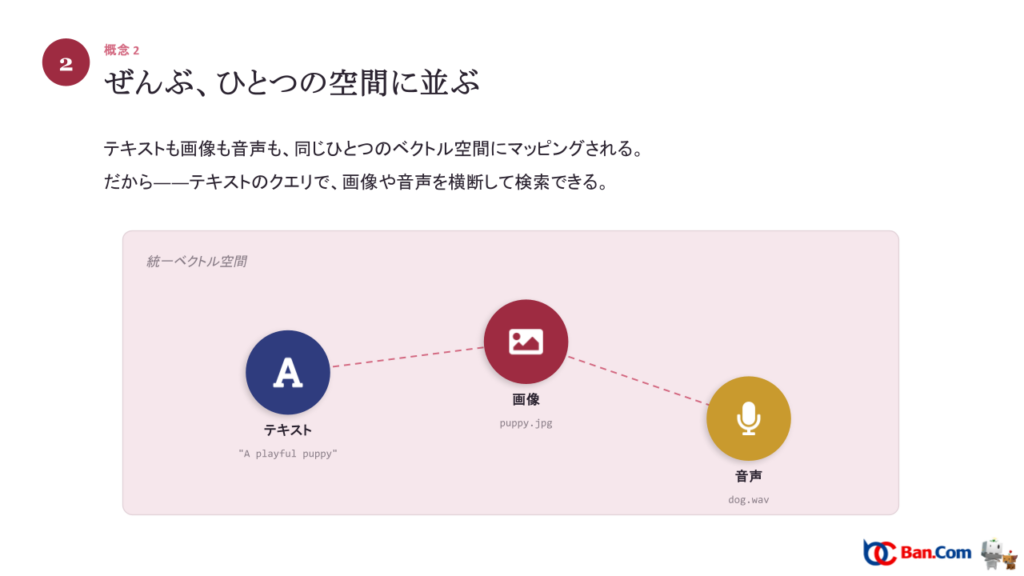
ここが核心です。テキストも画像も音声も、同じひとつのベクトル空間にマッピングされます。「テキスト用の検索」「画像用の検索」と別々のしくみを動かしているわけではありません。空間がひとつだからこそ、テキストのクエリで画像や音声を横断して検索できるのです。
概念③:近さのものさし「コサイン類似度」

2つのベクトルの「向き」がどれだけ近いかを、−1〜1の数値で表したものがコサイン類似度です。値が大きいほど意味が近いと考えます。目安として、1.0 はほぼ同じ意味(同じ文・自分自身)、0.6 あたりは近い関係、0.1 まで下がると無関係なもの同士、といった感覚です。
デモ①:テキストで検索したら、音声がヒットした
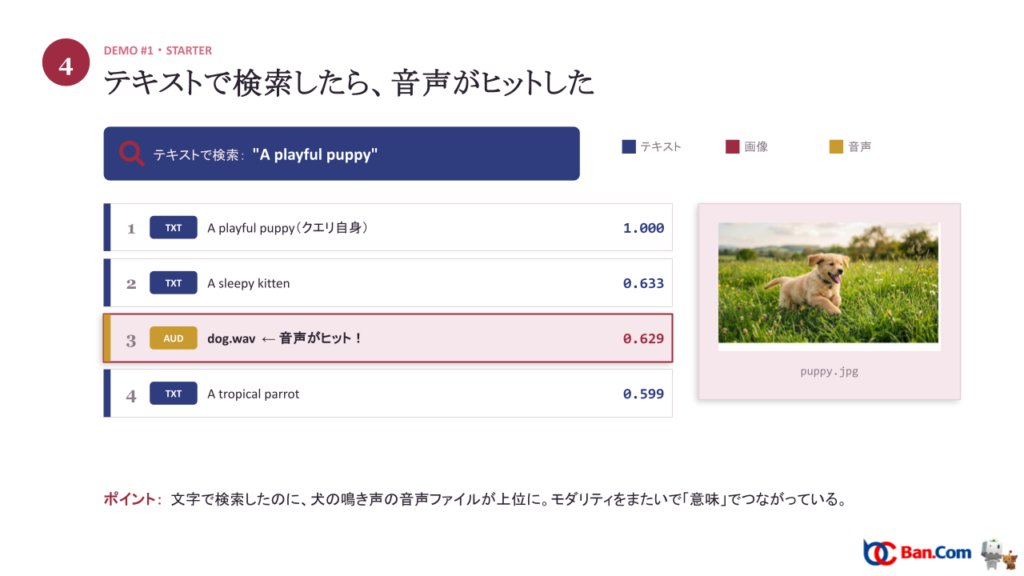
「A playful puppy(元気な子犬)」というテキストで検索してみます。結果は次の通りでした。
| 順位 | 種別 | ヒットしたもの | スコア |
|---|---|---|---|
| 1 | テキスト | A playful puppy(クエリ自身) | 1.000 |
| 2 | テキスト | A sleepy kitten | 0.633 |
| 3 | 音声 | dog.wav ← 音声がヒット! | 0.629 |
| 4 | テキスト | A tropical parrot | 0.599 |
文字で検索したのに、犬の鳴き声の音声ファイルが上位に食い込みました。モダリティ(データの種類)をまたいで「意味」でつながっている、という最初の手応えです。

さらに「I like to eat bananas」で検索すると、上位はバナナをかじる音・りんごをかじる音・コーヒー豆の音といった「食べ物を食べる音」ばかり。意味の近いものが、種類を超えてまとまって並ぶ様子が見てとれます。
種明かし:やっていることはとてもシンプル

魔法のように見えますが、手順はシンプルです。
- 検索したい文・画像・音声を、すべて同じ方法でベクトルに変換しておく
- クエリも同じ方法でベクトルに変換する
- クエリに近い点から順番に並べる ―― ただそれだけ
空間がひとつだから、横断検索が「特別なこと」ではなく自然にできてしまう。これが仕組みの正体です。
デモ②:手描きのスケッチで、実物の写真を引く
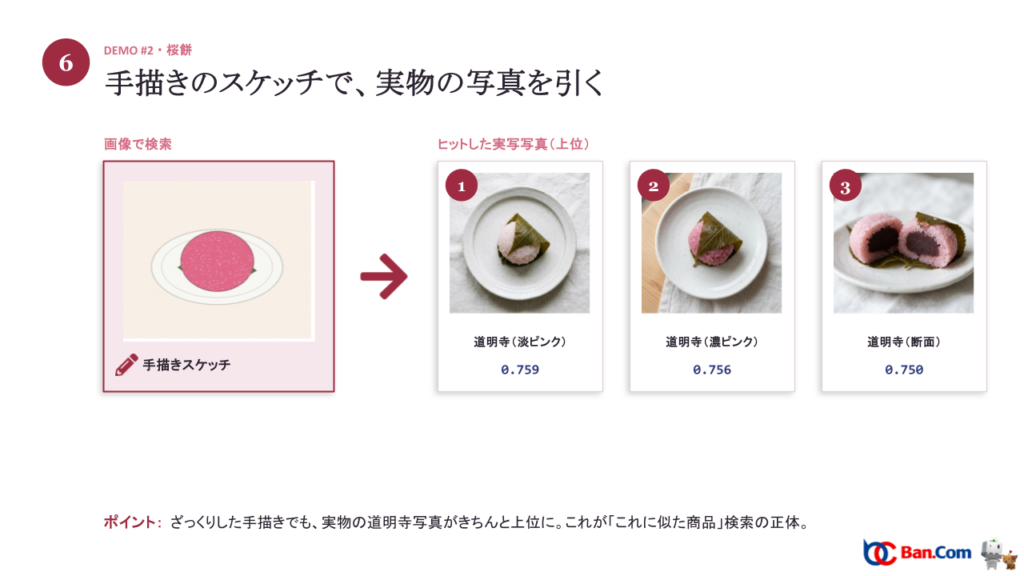
次は画像で検索します。お皿に淡いピンクの丸が乗っただけのざっくりした手描きスケッチを投げると、上位3件はすべて実物の道明寺(桜餅)の写真でした(淡ピンク 0.759、濃ピンク 0.756、断面 0.750)。これが、ECでよく見る「これに似た商品」検索の正体です。
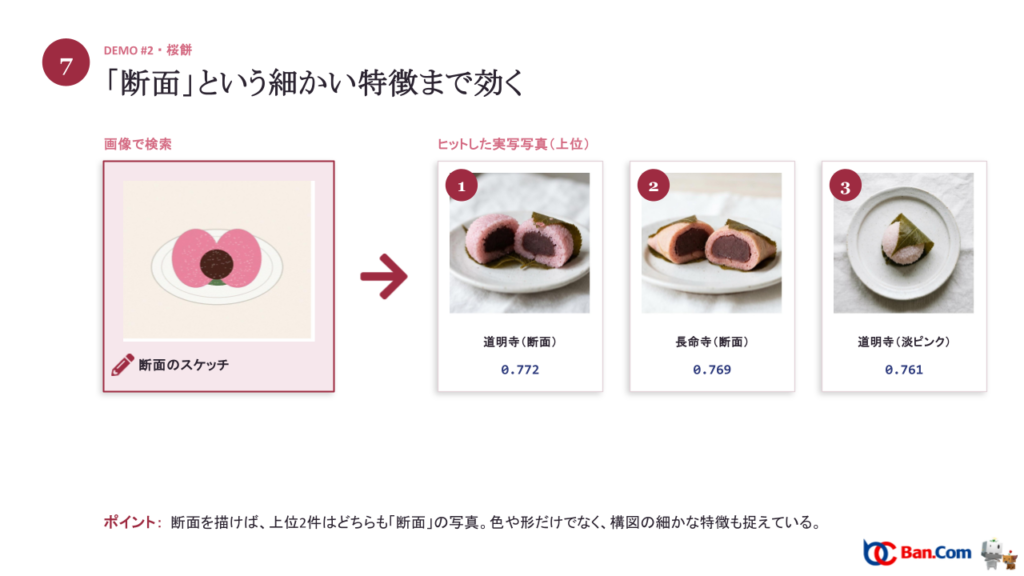
さらに「断面」を描いたスケッチで検索すると、上位2件はどちらも「断面」の写真がヒット。色や形だけでなく、構図という細かな特徴まで捉えていることがわかります。
デモ③:「ざらざら」も、ことばで検索できる

「ざらついた紙のテクスチャ」というテキストで画像を検索すると、大理石・細かいノイズ・粗い紙といった質感画像が上位に並びました。色や形の名前がなくても、「ざらざら」「高級感」といった言葉にしづらい質感が、そのまま検索の手がかりになるのです。

一方、夕焼け色・放射状の画像そのもので検索すると、1位のスコアは 0.923。先ほどのテキスト→画像が最高でも 0.4 前後だったのと比べ、画像どうしだとスコアがぐっと高く出ます。この「種類による差」が、次の落とし穴につながります。
落とし穴:スコアの絶対値で、モダリティをまたいで比べない

同じ「A sleepy kitten」で検索しても、ヒットした種類ごとにスコアの出方はまるで違います。テキスト最上位は 1.00、音声最上位は 0.74、画像最上位は 0.43。ここで「画像だけスコアが低い=画像はうまく検索できていない」と考えるのはよくある誤解です。
正しくは、空間は同じ。クエリの長さや、空間内での点の広がり方の違いでスコアの目盛りがずれているだけです。だからこそ、種類の違うもの同士をスコアの絶対値で直接比べてはいけません。
実装のヒント:だから「型」を捨てない

対策はシンプルで、アイテムごとに modality(text / image / audio)という「型」を保持しておくこと。型を持たせておくと、次のような場面で効いてきます。
| 場面 | 型が必要な理由 |
|---|---|
| 表示 | text / image / audio で画面の見せ方が変わる |
| 絞り込み | 「画像だけ」「音声だけ」のフィルタに型が要る |
| スコア補正 | 種類ごとに目盛りが違うので、別々にしきい値を決める |
| 再処理 | 再変換のとき、元のファイル種別と前処理が必要 |
実装そのものは軽量です。APIは embedContent 一本、クライアント側のコードは約50行ほど。難しいのはコードの量ではなく、「型を捨てない」設計の方だ、というのが今回の実感です。
まとめ:持ち帰ってほしい3つ
- ぜんぶ同じ空間 ― テキストも画像も音声も、ひとつのベクトル空間に並ぶ
- 横断して検索できる ― テキストのクエリで、画像も音声も一度に引ける
- スコアは型ごとに見る ― モダリティをまたいで絶対値で比べない
埋め込みは、RAGやセマンティック検索、類似商品レコメンドなど、これからのAI活用の土台になる技術です。「難しそう」と身構えるより、まずは桜餅で一度さわってみる。そこから景色がずいぶん変わります。ぜひスライドを開いて、一緒に試してみてください。
マルチモーダル埋め込みや社内検索・RAGの導入については、株式会社バンコムまでお気軽にご相談ください。
株式会社バンコム 代表 山口清秀